



.jpg)


当前位置:首页»企业

- 企业简介
-
作为中国自动化领域的权威旗舰网络媒体,控制网创立于1999年7月,是中国举行的第十四届IFAC (International Federation of Automatic Control)大会的中国官方组织机构的唯一指定网站。控制网是中国自动化学会专家咨询工作 委员会(ECC)的秘书处常设之地。是北京自控在线文化传播有限公司开设的网站。
- 公司类型:其他
- 联系方式
-
- 控制网
- 地址:北京市海淀区上地十街辉煌国际2号楼1504室
- 邮编:100085
- 电话:010-57116291 / 59813326
- 传真:010-59813329
- 网址:http://www.kongzhi.net
- Email:mahongliang@kongzhi.net
- 联系人:市场部
- 案例详细
-
标题 优化机器人多处理机控制系统性能方法 技术领域 传感器 行业 简介 分析了有腿的步行机器人控制器性能瓶颈的产生原因,提出优化机器人多处理机控制系统性能的有效方法。 内容
关键词:机器人;乒乓效应;Cache中数据一致;互斥锁机制 唐俊奇(1967—)
唐俊奇(1967—)
男,工学学士,湄洲湾职业技术学院副教授、高级工程师,研究方向为计算机系统结构、计算机网络。
由于人工智能、计算机科学、传感器技术及其它相关学科的长足进步,使得机器人的研究在高水平上进行,同时也为机器人控制器的性能提出更高的要求。由于机器人控制算法的复杂性以及机器人控制性能的亟待提高,许多学者从建模、算法等多方面进行了减少计算量的努力,但仍难以在串行结构控制器上满足实时计算的要求。因此,必须从控制器本身 寻求解决办法。其中最有效的方法就是采用多处理器作并行计算,提高 控制器的计算能力。如:有腿的步行机器人,其控制器采用多CPU(多处理机)结构(多处理机结构)控制方式[1]即:上、下位机二级分布式结构,上位机负责整个系统管理以及运动学计算、轨迹 规划等。下位机由多个CPU(处理机)组成,每个CPU控制一个关节运动,这些CPU和主控机联系是通过总线形式的紧耦合。这种结构的控制器工作速度和控制性能明显提高。在该控制器中多处理机系统的性能则成为机器人运动的瓶颈。
在下位机的多处理机系统中,每个处理机中都引入一独立的Cache,由于Cache的引入缩短了访存时间,减少互连网络、存储器的带宽压力和冲突,可以有效地克服了因多处理机系统性能所导致的瓶颈问题,但同时也产生了Cache中共享数据的一致性问题。为此本文着重阐述解决Cache中共享数据的一致性问题的方法。
1 由CACHE数据导致机器人控制器性能降低的原因分析[2-6]
有腿的步行机器人,其控制器采用多个CPU结构(多处理机结构)控制方式,在下位机的多个CPU(处理机)中,每个处理机控制一个关节运动。为了使高速缓存起到更大的作用,我们对现有协议中的并行算法要做一定的改动。比如,在数据项被访问前就将一组数据项预先放入高速缓存的算法可以产生更高的性能。高速缓存的关键特性是以连续单元的块的形式组成的。当处理器首次引用某个块的一个或几个字节后,这个块的所有数据就会被传送到高速缓存中。因此,如果引用这个块中的其他数据时,该主存已在高速缓存中而不必从主存中调用它。如果高速缓存所使用的块的大小和编译器存储数据的方法已知的话,并行算法就可以利用高速缓存的这一特性。当然,这种方法将大大地依赖于执行这个程序所使用的实际系统的情况。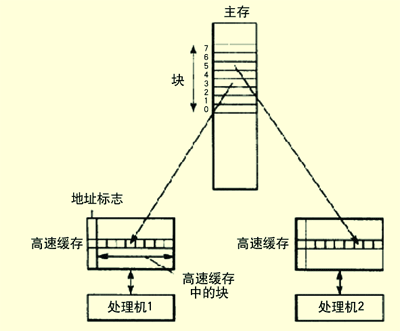
图1 高速缓存中假共享之所以要在高速缓存中使用块的原因是:顺序程序的基本特性和引用的时间局部性(temporal locality)(也就是说存储器引用倾向于接近以前存储器引用)。在多处理机系统的高速缓存中使用连续单元块的主要缺点是:在多处理机系统中,不同的处理器可能需要同一个主存块的不同部分而不是相同的字节。尽管实际数据不共享,但如果一个处理器对该块的其他部分写入,则这个块在其他高速缓存上的拷贝就要全部地进行更新或者使无效。这就是所谓的假共享(false sharing),它对系统的性能有负面的影响。图1展示了假共享。在图1中,一个块由8个字组成,从0到7。两个处理器访问同一块但不同部分(处理器1访问字3,而处理器2访问字5)。假设处理器1写了字3,则高速缓存一致协议将更新或者使处理器2中的高速缓存块无效,即便处理器2永远也不访问3。假设现在处理器2又改动了字5,则高速缓存一致协议反过来又要将处理器1中的高速缓存块进行更新或者使无效,而处理器1也许也永远不会访问字5。这样下去,就会导致高速缓存块的乒乓效应(ping-ponging)。从而降低了控制器的计算能力。
2 Cache中数据一致性问题的解决方法
从硬件的角度来看:现有两种解决Cache一致性硬件算法,但是都存在各自的问题:一是基于共享总线的多处理机系统监视(Snoopy)协议,这种算法在处理机数目较多时,总线的负载压力过大它将成为整个系统的瓶颈。另一种硬件算法为目录表法,这种算法使得存储器开销大;实现一致性时,延尽时间较长;而且扩展能力也差。随着系统中处理机数目的增加和多处理机系统的发展,硬件算法更加显示出其缺点和局限性。这样的系统难以保证机器人在高速运动中所要求的精度指标。我们必须寻找一个新的路径以满足现实需求。
2.1 编译时设置用基于访存时标使Cache中数据一致
基于访存时标的方法这种方法的基本思想是每一共享数据都带有一时钟标计,而Cache中的每一字(一块),以及读写访存也都带有一时钟标计。若Cache中的一字被修改一次,则字的时钟加1,当对Cache中的一字进行访问时,若访问时标大于或等于Cache中字的时标,说明访问的是最新版本,否则访问主存,例如:
/*LOOPiL*/
Doall i1=1 ,n1
.
.
X(f0)
.
.
end doall
.
.
/* LOOPi3 */
Doall i3=1,n3
.
.
.... X(p0)
.
.
end doall
程序中的数组X有一时钟,其初始值为0,在LOOPi1;,之后,X的时钟为1,经LOOPi2;之后,X的时钟为2。在LOOPi3;,中,若Cache中X的时钟标计为0或为1,则说明不是最新版本,若为2,则说明Cache中的数据有效。
基于访存时标的方法,借用了流分析访存标志法的思想但是它在更复杂分析的基础上,引入动态成份—时标使之在一定程度上使失效的选择性更加充分,提高了效率。
2.2 使用互斥锁机制避免假共享产生[2-6]
有腿的步行机器人的下位机由多个CPU(处理机)组成,每个CPU控制一个关节运动,可以创建n个线程与之对应。为了便于分析,避开机器人关节运动的复杂性,而以对数组a[1000]求和这个简单的例子来进行说明如何避免共享存储器sum的乒乓效应。
在此笔者将创建n个线程,每个线程都要重复地从列表中获取元素并加到它们的和中。当所以的元素都被取走后这些线程就将它的部分和加到共享单元sum中,如下程序是按照图4所示的结构创建共享数据。各个线程通过共享单元global_index获取a[ ]数组的下一个未加元素。在这个index所指的数组元素被读后,index就会加1,从而指向下一个未加元素,为下一次元素的获取做好准备。结果所在的主存单元将sum,并将同样被共享且使用锁机制来保护对其的访问。
有一点非常重要,那就是不能在临界段外访问全局下标gloabnl_index。这包括察看下标是否达到最大值的操作。如下语句:
while (global_index< array_aize)……
需要访问global_index,在while内的语句体已经被执行之前,这个下标可能被其他的线程改变。在本代码中,使用一个局部变量,local_indexgo 存放当前读到global_index的值,以便更新部分和以及检查下标是否达到了最大值。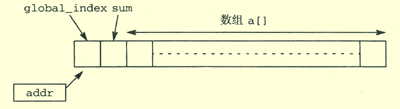
图 2 在互斥锁机制中同时使用sum和global_index共享存储单元在本代码中,使用了互斥锁机制,而没有使用条件变量。使用该方法的程序如下:
# include < stdio.h>
# include < pthread.h>
# include arrau_size 1000
# include no_threads 10 /* shared data */
int a[array_size]; /* array of numbers to sum */
int global_index =0; /* global index */
int sum =0; /* final result,also used by slaves */
pthread_mutex_t mutex1;
void * slave(void * ignored){ /* slave threads */
int local_index,partial_sum =0;
do { /* get next index into the array */
pthread_mutex_lock(&mutex1);
/* read current index & save locally */
local_index = clobal_index;
global_index ++;
/* increment clobal index */
pthread_mutex_unlock(& mutexl);
if (local_index<array_size)
partial_sum += * (a+local_index);
}while(local_index<array_size);
pthread_mutex_lock(&mutexl);
/* add partial sum global sum */
sum += partial_sum;
pthread_mutex_unlock (& mutexl);
return( ); } /* Thread exits */
main ( ) {
int i;
pthread_t thread[no_threads]; /* threads */
pthread_mutex_init(& mutexl,NULL);
/* initialize mutex */
for ( i=0; i<array_size; i++) / * initialize [] */
a[i]=i+1;
for (i=0;i<no_threads; i++)
/* initialize a[] */
if(pthread_create(&thread [i],NULL,slave ,NULL) !=0)
perror(“pthread_create fails”);
for (i=0;i<no_threads; i++) /* join threads */
if (pthread__join(thread [i],NULL !=0)
perror(“pthread_join fails”);
printf(“The sum of 1 to *i is &d\n”,array_size,sum);} /* end of main */
SAMPLE OUTPUT
The sum of 1 to 1000 is 500500
2.3 用Java监控程序的方法避免假共享产生[4]
在Java中有监控程序的概念。Java中的关键词Synchronized可以使方法中的一段代码成为线程安全的,它可防止多个线程间的冲突。
仍以对数组a[1000]求和为例,在编程时采用动态平衡的方法来负责任务的分配,下面是利用JAVA监控程序以避免共享存储器sum的乒乓效应用于Java的监控程序方法(利用该Java监控程序实现:一个线程承担所有的工作)。
public class Adder {
public int[] array;
private int sum =0;
private int index =0;
private int number_of_threads =10;
private int threads_quit;
public Adder( ) {
threads_quit =0;
array =new int [1000];
initializeArray ( );
startThreads ( ); }
public synchronized int getNextIndex (){
if (index<1000) return(index++);
else
return(-1); }
public synchronized void addpartialsum(int partial_sum) {
sum=sum + partial_sum;
if(++ threads_quit = = number_of_threads)
System.out.println(“The sum of numbers is ”+sum); }
private void initializeArray () {
int i;
for(i=0; i<1000, i++) array (i) =i; }
public void startThreads ( ) {
int i=0;
for (i=0;i<10;i++) {
AdderThread at = new AdderThread(this,i); }}
public static void main (String arge[ ]) {
Adder a= new Adder ( ); }}
class AdderThead extends Thread
{
int partial_sum =0;
Adder parent;
Int number;
public AdderThread(Adder parent, int number)
{ this.parent=parmet;
this.number=number; }
public void run ( ) }
int index=0;
while (index !=-1){
partial_sum=partial_sum + parent.array[index];
index=parent.getNextIndex( ); }
system.out.println(“partial sum from thread”+ number +”is”
+ partial_sum);
parent.addpartialSum(partial_sum);}}
3 结束语
仿真实验表明:有腿的步行机器人,在其下位机的多处理机系统中,由于采用了编译时设置用基于访存时标、互斥锁机制、Java监控程序这些方法使Cache中数据保持一致,充分发挥了Cache的优点缩短了访存时间,减少互连网络、存储器的带宽压力和冲突,有效地克服了因多处理机系统性能所导致的瓶颈问题,从而提高了机器人多处理器计算机系统的性能。
参考文献:
[1]普杰信,严学高.机器人分布式计算机控制系统结构的性能分析[J].机器人,1994,16(3)144-149.
[2]唐俊奇.多处理机系统Cache共享数据乒乓效应的研究[J].莆田学院学报,2006,13(2)51-54.
[3]孙强南,孙昱东等编著.计算机系统结构[M].北京:科学出版社,2000.
[4]殷兆麟.Java语言程序设计[M].北京:高等教育出版社,2002.
[5]TMASEVIC M., AND V.MILUTINOVIC(1993),The Cache CoherenceProblem in Shard-Memory Multiprocessor:Hardware Solutions, IEEE CS Press,Los Alamitos,California.
[6]薛燕,樊晓桠,李瑛. 多处理机系统中数据Cache的一种优化设计[J].微电子学与计算机,2004,21(12),191-194.

电话:010-62669087 控制网版权所有未经许可不得转载
地址:北京市海淀区上地十街辉煌国际5号楼1416室(100085)
版权所有 控制网 京ICP备14036844-2号 北京市公安局海淀分局备案号:11010802023656号
北京市公安局海淀分局备案号:11010802023656号
地址:北京市海淀区上地十街辉煌国际5号楼1416室(100085)
版权所有 控制网 京ICP备14036844-2号