



.jpg)


当前位置:首页»企业

- 企业简介
-
作为中国自动化领域的权威旗舰网络媒体,控制网创立于1999年7月,是中国举行的第十四届IFAC (International Federation of Automatic Control)大会的中国官方组织机构的唯一指定网站。控制网是中国自动化学会专家咨询工作 委员会(ECC)的秘书处常设之地。是北京自控在线文化传播有限公司开设的网站。
- 公司类型:其他
- 联系方式
-
- 控制网
- 地址:北京市海淀区上地十街辉煌国际2号楼1504室
- 邮编:100085
- 电话:010-57116291 / 59813326
- 传真:010-59813329
- 网址:http://www.kongzhi.net
- Email:mahongliang@kongzhi.net
- 联系人:市场部
- 案例详细
-
标题 一个实时历史数据存储文件结构的设计 技术领域 仪器仪表 行业 简介 内容  张永军(1981-)
张永军(1981-)
男,硕士研究生,(华北计算机系统工程研究所 北京 100101)主要研究方向为实时数据库,MES。
摘要:实时数据库是大数据量的应用,因此它的存储方案必须具有很高的读写效率。同时实时库的应用要求满足长期性和鲁棒性。但是长期性和鲁棒性是相互矛盾的。本文给出了一个缓和长期性和鲁棒性矛盾的实时历史数据库文件系统的解决方案。
关键词:实时数据库;存储;文件系统Abstract: Real time database is an application of mass data. Therefore, its storage scheme requires not only high efficiency of read and write, but also longtime and robustness. In fact, it is contradictory between longtime and robustness. A solution for real time historical database file system is presented in this paper, which satisfies the said requirements.
Key words: Real time database; Storage; File system architecture
1 引言
现代工业的飞速发展,尤其是计算机在工业过程控制中的广泛应用,极大地提高了生产过程的自动化程度,同时也对工业监控软件提出了更高的要求。系统一方面需要维护大量共享数据和控制知识;另一方面其应用活动有很强的时间性,要求在一定的时刻和一定的时间区段内对外部环境采集数据,按彼此间的联系存取已获得的数据和处理采集的数据,再及时做出响应。同时,他们所处理的数据往往是“短暂”的,即只在一定的时间范围内有效,过时则无意义,所以这种应用同时需要数据库技术和实时数据处理技术。但传统的数据库系统旨在处理永久性数据,其设计与开发主要强调维护数据的完整性、一致性,提高系统的吞吐量和降低系统代价,根本不考虑与数据及其处理相关联的定时限制,因而传统的商务和管理事务型 DBMS 不能满足这种实时应用的需求。而传统的实时系统虽然支持处理的定时限制,但它们典型地是针对具有简单结构与联系、稳定并且可预报的数据的要求,不涉及维护共享数据的完整性、一致性。因此,只有将数据库与实时系统两者的概念、技术、方法与机制“完善”地集成在一起的实时数据库系统才能同时支持定时性和一致性要求。
2 实时数据特点
由于实时数据库与时间紧密相关,它所存储的数据通常是指那些基于时间的连续模拟量或数字量(例如温度、压力、流量、阀门开关等),这些数据有如下四个鲜明特点:
(1)数据量庞大。流程工业中一套工业设备从投入使用到设备报废封存,一般都要经历至少几十年的运行时间,在运行期间需要连续记录生产过程中的关键数据,作为改进生产工艺、提高生产效率、监视故障信息的重要参考。但是经过数据长年累月的累积,其庞大程度几乎难以想象。我们以一个记录1000个历史记录点的实时历史数据库为例,假如记录类型都为浮点型,记录周期为1秒,该系统运行1年大致的数据量为:
8×10000×365×24×3600=2522880000000字节(约2350G)
此处历史记录保存的信息包括记录点、记录值和相应的时间戳,共8字节。工厂记录点的多少根据工厂的规模而不同,但是一般工厂的采集点都要上万个。如此规模的历史数据库运行几年后数据量会非常庞大,数据库查询时效率也必然很低。
(2)时效性:每个需要记录的值都与时间相关,一秒钟之后的数据与一秒钟之前的数据可能就不一样了。因此,在记录值的同时必须通过某种方法将其对应的时间(时间戳)也记录下来。
(3)存储格式相对简单、固定和独立。虽然从应用的角度看,保存的数据有I/O整型、实数型、离散型、内存整型、开关类型等,但是从技术实现的角度看,都可以总结为1字节,2字节或者4字节数据三种情况,同时历史记录点之间不存在依存关系,即不存在类似关系数据库中数据之间错综复杂的关系,所以记录格式少而固定,没有复杂的关系。
(4)保存的时间间隔相差很大。通常在流程工业现场存在这样的情况,就是某些记录点变化频率非常高,甚至是几十毫秒变化一次,而有些则是很长一段时间才会发生变化,据此必然对实时历史数据库的存储提出了异样的保存要求,所以历史数据存储时必须统筹兼顾又细化要求。
由于数据量的庞大性,我们无法将实时数据全都存到关系数据库中。即使可以,进行实时数据库产品开发后的最终产品受关系数据库接口的制约,灵活性、效率等无法保证,而且项目实施成本较高。在此情况下,我们设计了一个存储数据文件的格式,该数据文件可以提高系统运行效率和数据压缩率,适应复杂的生产运行环境,具有较好的市场和应用前景,同时能满足历史数据库的长期性和鲁棒性。下面讲阐述该数据文件的结构。
3 文件结构
存储系统使用两种类型的文件:“数据文件索引文件”(以下简称索引文件)和“数据文件”。索引文件只能有一个,它记录所有数据文件的基本信息;数据文件可以有多个,它们记录实际的生产数据。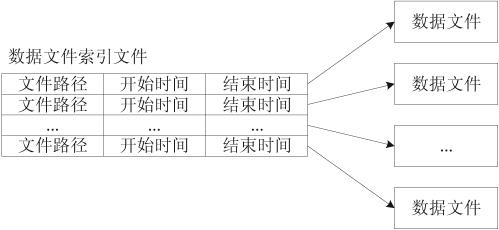
图1 文件结构图如上图所示,索引文件由一些索引项构成,每一项对应一个数据文件。索引项中的内容包括与其相对应的数据文件的路径、开始时间和结束时间。所有索引项以开始时间为序排列。在这里对数据文件进行详细介绍。
数据文件由文件头、点目录、数据目录和数据区四部分构成
3.1 文件头
文件头包含此文件的基本信息,结构如图1所示。
图2 文件头结构图3.2 点目录
点目录存储点在数据目录中的第一项的位置和点类型。为了查找方便,其中的点严格按点id(点的唯一标识,一个整数)排序。每个点目录项长8字节(64位),结构如图3所示。
图3整个点目录就是一个上述结构的数组,它能包含的项数由文件头的“最大点数”决定。
3.3 数据目录
数据目录记录了点使用的所有数据片,数据区的最小分配单元,详见数据区),它是由数据目录项构成的数组,每个数据目录项对应一个数据片,其大小也占用8字节,结构如图4所示
图4其中,开始时间是它所对应的数据片的开始时间,这是一个相对于文件头中的“开始时间”的值,以秒、0.1秒或0.01秒为单位。下一项索引是同一个点使用的下一个数据目录项的索引。这样,每个点使用的所有数据目录项构成了一个链表。
数据区是真正保存历史数据的位置,为提高读写效率,将它划分为大小相等的数据片,根据实际效率测试结果,片的大小可取1024、2048、4096等值(后文的讨论以2048字节为例),但应保证其大小是磁盘扇区大小的整数倍。数据区的分配以片为单位。下图说明了点目录、数据目录和数据片之间的关系。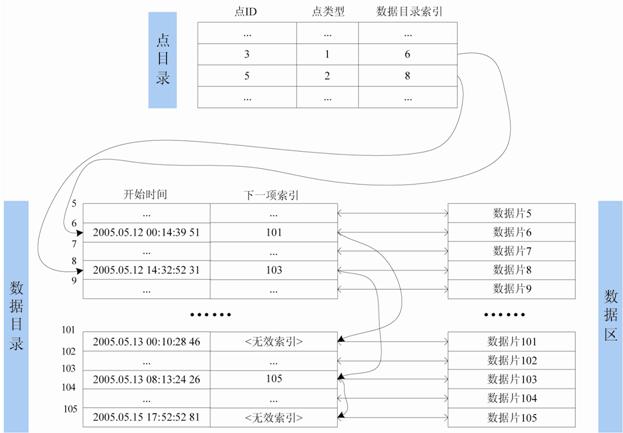
图5 数据区结构图如图5所示,数据目录项和数据片具有一一对应的关系,第n个数据目录项对应的就是第n个数据片。点3的第一个数据目录项是6,第二个数据目录项是101,所以它使用的数据片也是第6片和第101片;同理,点5使用的数据片是8、103和105。
当某个点需要一个新的数据片时,分配给它的总是当前使用的最后一个数据片的下一个,如图6所示。
图6中每个小格代表一个数据片,一开始,点1—5分别使用数据片1—5;一段时间之后,点2的数据写满了2号数据片,这时就必须给它分配新的数据片,而分配给它的将是6号数据片;又过一段时间,点5也需要新的数据片了,这时将分配给它7号数据片。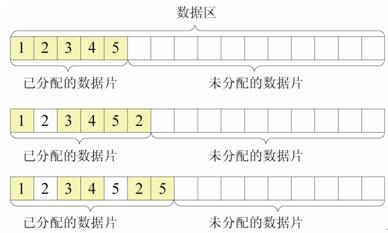
图6从图6中也可以发现,同一个时间段内,点2写的数据量最大,点5次之,点1、3、4则相对较少。我们把单位时间内一个点写的数据量称为点的速度,简称点速。同一个点在不同时刻的点速也是不一样的,但总体上看,当点数达到一定的规模以后,所有点的点速将呈正态分布。

图7图7是数据片中的数据存储结构:
开始时间是一个绝对时间,本数据片中的所有数据的时间戳都晚于它。它的取值有两个选择,一是上一个数据片最后一个数据的时间,一是本数据片第一个数据的时间,为了查询时的方便,选择前者。数据片存储“上一片的最后一个数据”也是为了特殊情况的查询方便。特别的,如果没有上一个数据片,则开始时间为本片的第一个数据的时间,“上一片的最后一个数据”的质量字段将被置为invalid(无效)。
4 二级索引文件管理
文件结构设计好之后,文件的存储管理又是一个问题。因为在文件使用和管理中,对于一个包含大量文件的文件夹,在打开的时候要消耗很长时间,而只有少量文件的文件夹在打开的时候需要的时间几乎可以忽略。尝试打开一个包含有10000个文件(每个文件大小为10M)的文件夹,打开所需的时间在10秒钟以上,而一个只有10个文件的文件夹,打开的时间少于0.5秒钟。从直观的角度上看,一个目录的文件过多会严重影响系统的访问性能,因此有必要将大量的文件建立子目录进行存储。
我们设定系统中的数据文件(每个文件大小固定为10M)为10000个,从测试效果上对这个问题给出确定性答案,并研究在实时历史数据库中可以采用的有实际意义的分配方案。由于文件总数是一定的,因而可以说我们的研究是建立在对不同目录级数的比较之上,为了方便,将一个目录下存储10000个文件称为单级目录方案,而分成若100个子目录存储则称为二级目录方案(每个子目录存储10个文件)。表1为两种存储情况下查找一个文件的时间。
表1 单级和二级目录查询时间比较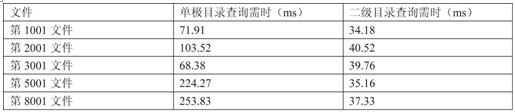
从对比中我们可以清晰的看出,两级目录在同样条件下,相比与根目录下的文件访问速度有很大的优势。而多级目录的组织原则如下(设单级目录为A):
(1)当A文件大小不超过1簇(在FAT32文件系统中,存储的单位是扇区,每一个扇区的大小是固定的512字节,若干个扇区组成一个簇,每个簇可以包含的扇区数必须是2的整数次方,这样簇的大小可以是512B,1k,2k,4k,8k,16k,32k或者64k其中之一)的时候,是不需要设立子目录的,所有的文件在一簇空间之内都可以访问到;
(2)当A的文件大小超过1簇的时候,若设立子目录,则所有项都需要通过两级目录才能 够访问,其对硬盘的平均访问次数为2。 若不设立子目录,则A的目录文件就需要分配新的簇,若A的目录文件共需要N个簇,对文件的访问遵从平均分布,则硬盘的平均访问次数T为:T=1×1/N+2×1/N+3×1/N+…+N×1/N,
令T=2,对这个关于N的函数求解得N=3。也就是说,在A的目录文件总共需要3个簇的时候,其平均硬盘访问次数达到2, 而在此之前,单级目录的效率会更高一些。对于大小为16KB的簇,当存储名字不超过13个字符的文件时,目录文件为3簇大小的时候,其目录下一共有1024×16×3/(32×2) =768个文件。二级索引结构如图8所示。
图8 二级索引结构5 结论
本文给出了一个实时数据库存储文件的实现方案,该方案可以提高实时数据库中历史数据库的存取速度,该方案已经在和利时的实时数据库HIRIS中得到应用,取得了不错的效果。
其他作者:
刘 波(华北计算机系统工程研究所 北京 100101)
参考文献:
[1] Ben Kao、Hector Garcia-Molina:AN OVERVIEW OF REAL-TIME DATABASE SYSTEMS.
[2] 刘云生.现代数据库技术.国防工业出版社,2001.
[3] [美」Raghu Ramakrishnan著,周立柱,张志强等译.数据库管理系统原理与设计.清华大学出版社,2004.
[4] 马国华.实时数据库及其管理系统,自动化博览,2002,(5).
[5] 周东球等.先进控制软件系统实时数据库的设计,自动化博览,2002,(7).

电话:010-62669087 控制网版权所有未经许可不得转载
地址:北京市海淀区上地十街辉煌国际5号楼1416室(100085)
版权所有 控制网 京ICP备14036844-2号 北京市公安局海淀分局备案号:11010802023656号
北京市公安局海淀分局备案号:11010802023656号
地址:北京市海淀区上地十街辉煌国际5号楼1416室(100085)
版权所有 控制网 京ICP备14036844-2号